数据探索(数据清洗)② |
您所在的位置:网站首页 › 将数据导入python 求均值 › 数据探索(数据清洗)② |
数据探索(数据清洗)②
|
Python介绍、 Unix & Linux & Window & Mac 平台安装更新 Python3 及VSCode下Python环境配置配置 python基础知识及数据分析工具安装及简单使用(Numpy/Scipy/Matplotlib/Pandas/StatsModels/Scikit-Learn/Keras/Gensim)) 数据探索(数据清洗)①——数据质量分析(对数据中的缺失值、异常值和一致性进行分析) 数据探索(数据清洗)②—Python对数据中的缺失值、异常值和一致性进行处理 数据探索(数据集成、数据变换、数据规约)③—Python对数据规范化、数据离散化、属性构造、主成分分析 降维 数据探索(数据特征分析)④—Python分布分析、对比分析、统计量分析、期性分析、贡献度分析、相关性分析 挖掘建模①—分类与预测 挖掘建模②—Python实现预测 挖掘建模③—聚类分析(包括相关性分析、雷达图等)及python实现 挖掘建模④—关联规则及Apriori算法案例与python实现 挖掘建模⑤—因子分析与python实现 数据探索(数据清洗)②—Python对数据中的缺失值、异常值和一致性进行处理 Python 处理数据Pandas读取保存数据Pandas数据清洗(重复值/缺失值/异常值)重复值处理① 用duplicated()方法进行逻辑判断是否有重复值②用duplicates(subset,keep,inplace)方法对某几列下面的重复行删除 缺失值处理①缺失值查找②缺失值删除③缺失值填充拉格朗日法插补 异常值处理①异常值查找②可以画箱型图异常值处理① 删除——先将异常值替换为na,然后用dropna()删除②视为缺失值——先将异常值替换为na,然后用缺失值处理方法处理(填充,插值等)比如用箱形图的办法,超过了上四分位1.5倍四分位距或下四分位1.5倍距离都算异常值,用中位数填充。再比如用标准差和均值,定义超过4倍就算异常值 Pandas数据规整(索引和列名调整/数据内容调整/排序/数据拼接/透视)索引和列名调整索引① 设定索引② 修改索引,直接赋值给Index即可 如何使用索引列调整①筛选需要的列②修改列名 数据格式调整修改数据类型修改数据内容①去除空格②替换字符③截取部分字符 数据排序按索引排序按列值排序 数据拼接行堆叠concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False,copy=True) 列拼接merge(left_data,right_data,on,left_on,right_on,suffixes,how,left_index,right_index) 数据透视unstack/stack Python 处理数据Python中的插值、数据归一化、主成分分析等与数据预处理相关的函数。 Pandas 官网参考具体参数:https://pandas.pydata.org/docs/pandas.pdf pd.read_excel('data.xls') # 读取Excel文件,创建DataFrame。 pd.read_csv('data.csv', encoding = 'utf-8') # 读取csv文本格式的数据,一般用encoding指定编码。 pd.read_table('data.txt',sep='\s+',encoding='utf-8',header=0,names='abcdefghij',index_col=['a','b'],usecols=list('abcdefg')) # 读取txt文件 pd.read_json('data.json',orient='values') data.to_excel("data1.xlsx",sheet_name='Sheet_name_1') data.to_csv('data1.txt', sep='\t', header=True,index=True) # 导出txt data.to_csv('data1.csv', encoding='gbk',columns=list('abcd'),header=False,index=False) # 导出csv data.to_json('data2.json',orient='records') # 导出json Pandas数据清洗(重复值/缺失值/异常值) 重复值处理 ① 用duplicated()方法进行逻辑判断是否有重复值 sportdata = 'data/sportdata.csv' # 体育数据 data = pd.read_csv(sportdata,encoding='gbk') # 读取数据,指定“学号”列为索引列 print(data.duplicated().value_counts())
subset:以哪几列作为基准列,判断是否重复,如果不写则默认所有列都要重复才算 keep: 保留哪一个,fist-保留首次出现的,last-保留最后出现的,False-重复的一个都不保留,默认为first inplace: 是否进行替换,最好选择False,保留原始数据,默认也是False # 删除重复值 data.drop_duplicates(subset=["学号"],keep='first',inplace=True) print(data.duplicated().value_counts())
先通过isnull函数看一下是否有空值,结果是有空值的地方显示为True,没有的显示为False;再通过isnull().any()直接看每一列是否有空值,这个是只要这一列有1个空值,结果就是True;如果想具体看哪几行有空值,可以再用data.isnull().values==True来定位。 print(data.isnull())
fillna(value,method,{},limit,inplace,axis) value: 可以传入一个字符串或数字替代Na,值可以是指定的或者平均值,众数或中位数等 method: 有ffill(用前一个填充)和bfill(用后一个填充)两种 {}: 可以根据不同的列填充不同的值,列为键,填充值为值 limit: 限定填充的数量 inplace: 是否直接在原文件修改 axis: 填充的方向,默认是0,按行填充 data1 = data[data.isnull().values==True] print(data1) print(data1.fillna(0)) # 0填充
先用describe()对统计字段进行描述性分析(仅能进行连续变量的处理),从结果上肺活量的最大值到到9999,坐位体前屈的最大值达到89,属于异常情况。 import pandas as pd # 导入数据分析库Pandas # print(data.describe()) outputfile = 'tmp/描述.xls' # 输出数据路径 data.describe().to_excel(outputfile, index=True)
四分位距(IQR)就是上四分位与下四分位的差值。而我们通过IQR的1.5倍为标准,规定:超过上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离的点为异常值。
更改数据类型,更改数据内容(去除空格标点符号/截取/替换/统一数据单位等),增加用于分析的辅助列 修改数据类型 data[['学号']] = data[['学号']].astype(str) # 转字符串 data[['年级代码']] = data[['年级代码']].astype(str) print(data.dtypes) 修改数据内容 ①去除空格 frame = pd.DataFrame([[' 你 ' , ' 和', '他'],['都', '很 ', ' 棒']], index=[1,2], columns=['hoin', 'hui', 'dfs']) print(frame) for i in range(len(frame.columns)): frame.iloc[:,i] = frame.iloc[:,i].str.strip() print(frame)
根据索引或列进行排序 按索引排序 data = pd.read_csv("data/sportdata.csv",encoding='gbk') print(data.head()) print(data.sort_index(ascending=False).head())
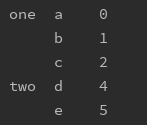
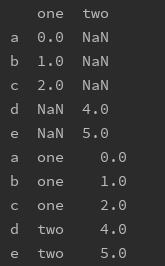
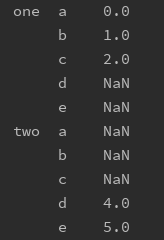
行堆叠和列拼接 行堆叠 concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False,copy=True)参数说明: objs: 拼接的series或dataframe axis:拼接轴方向,默认为0,沿行拼接;若为1,沿列拼接 join:默认外联’outer’,拼接另一轴所有的label,缺失值用NaN填充;内联’inner’,只拼接另一轴相同的label; join_axes: 指定需要拼接的轴的labels,可在join既不内联又不外联的时候使用 ignore_index:对index进行重新排序 keys:多重索引,便于区分来源表 sort: 按值排序 列拼接 merge(left_data,right_data,on,left_on,right_on,suffixes,how,left_index,right_index)参数说明: left_data/right_data: 需要合并的两部分数据,左右顺序不同,结果有可能不一样,具体要结合how来看 on: 连接键,当两个表的连接键名一样,可以直接用on,而不用left_on和right_on,可以是单键或多键 left_on/right_on: 如果两个表键名不一样,则分别指出,可以是单键或多键 suffixes: 如果两边键名相同的,想要做区分,可以使用此参数指定区分格式,如suffixes=(’_left’, ‘_right’) how:指定连接的方式,分为inner,left, right, outer,与SQL中的join一致,默认为Inner left_index/right_index: 如果需要连接的键是索引,就不用left_on/right_on,而是用这两个,也可以一个用left_on,一个用right_index,两都可结合使用 数据透视行或列维度转换 unstack/stackunstack是拆堆,将行索引透视到列,如果没有的可以用Na补充,stack是将列透视到行,均可选择透视的字段 s1 = pd.Series([0, 1, 2], index=['a', 'b', 'c']) s2 = pd.Series([4, 5], index=['d', 'e']) data = pd.concat([s1, s2],keys=['one', 'two']) print(data)
|

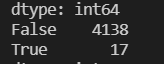
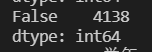



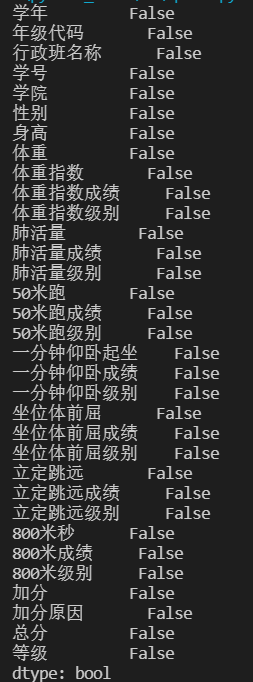




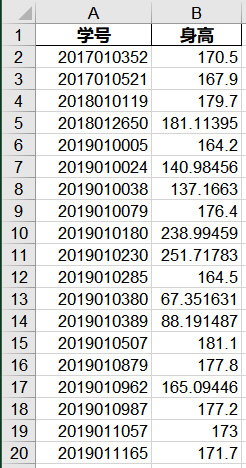

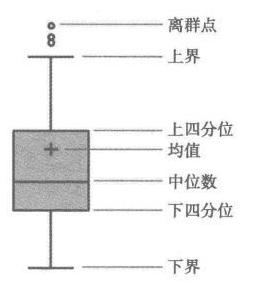
 如果数据需要服从正态分布。在3∂原则下,异常值如超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| 3∂) = 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述,比如这里我就指定超过4倍标准差就为异常值。
如果数据需要服从正态分布。在3∂原则下,异常值如超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| 3∂) = 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述,比如这里我就指定超过4倍标准差就为异常值。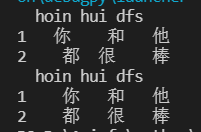
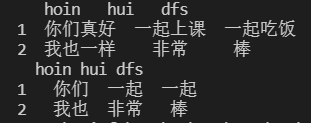


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |